Scaling Hotstar for Millions of Users with No Downtime, Miracle, or Engineering!!!


Table of contents
Overview
How many of you are familiar with OTT(over-the-top) platform "Hotstar", I guess many of you are familiar with it and for those who are not familar what "Hotstar" is, Disney+ Hotstar (also known as Hotstar) is an Indian brand of subscription video on-demand over-the-top streaming service owned by Novi Digital Entertainment of Disney Star and operated by Disney Media and Entertainment Distribution, both divisions of The Walt Disney Company.

The brand was first introduced as Hotstar for a streaming service carrying content from Disney Star's local networks, including films, television series, live sports, and original programming, as well as featuring content licensed from third-parties such as HBO and Showtime among others. Amid the significant growth of mobile broadband in India, Hotstar quickly became the dominant streaming service in the country.
This Platform is one of the most popular and live example of a Engineering miracle, Want to know why I said this just wait I will explain it shortly.
This Blog is a Case Study about How hotstar handles so many live users with almost zero downtime (~20M+ live streaming users) during IND vs NZ 2019 World Cup. Making the world record of 25M+ live streamers on their platform.

The concurrency pattern graph showing the whole story short 📈
I have breakdown the graph into parts or points to clearly understand it.
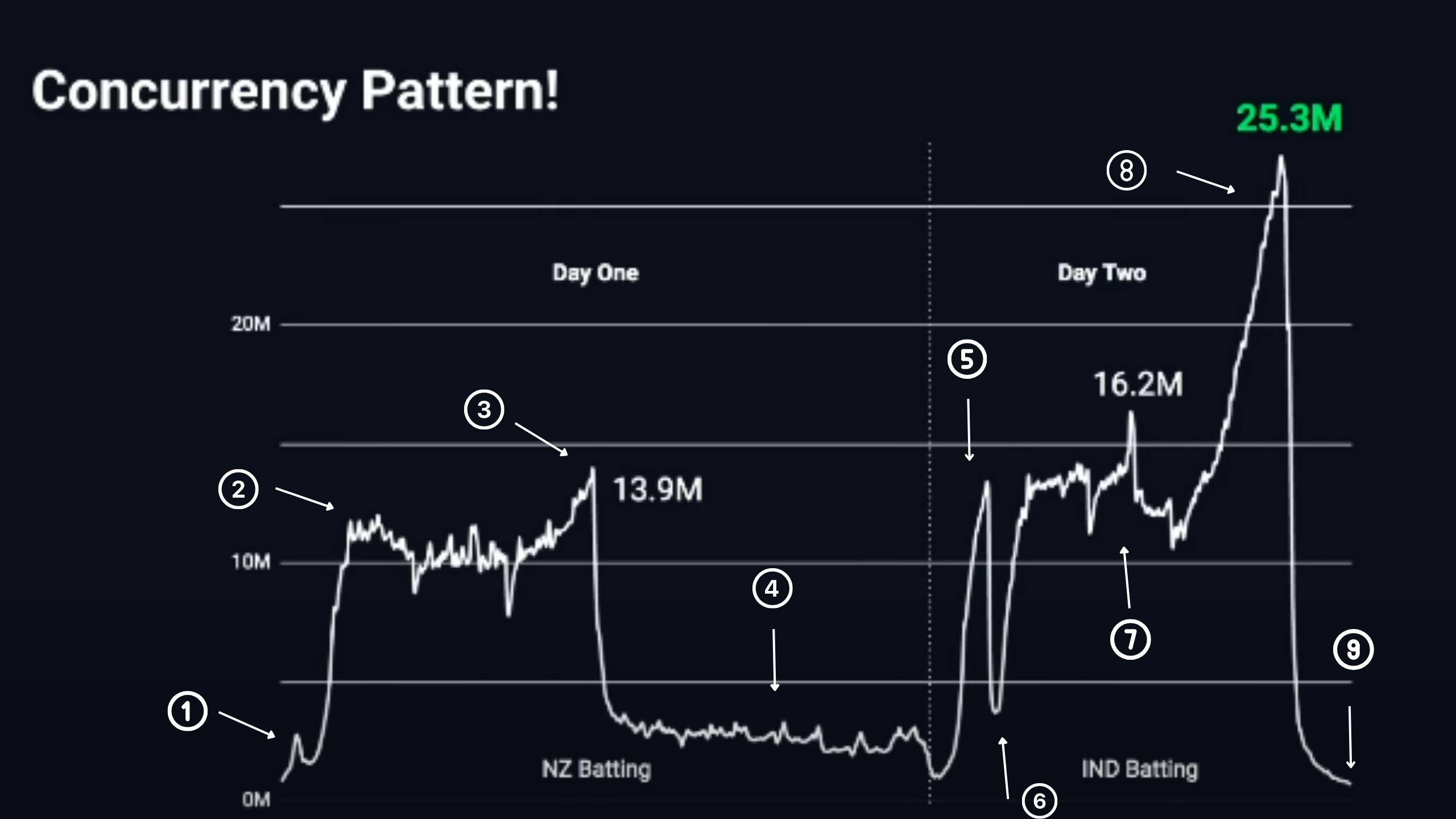
The above graph is showing the frequencies of the number of users watching during the entire match.
Let's understand the graph
- The Beginning
If you see in the graph the first small hike is at point 1. That is the time when the toss happens.
- Sudden hike from ~1.5M to 10M
As you can see from the graph the rise between point 1 to point 2 the rise take so fast to above 10M+ live streamers. At that time NZ starts batting.
- During NZ Batting
You can see a lot of Dips between point 2 and point 3 that is because of the strategic timeouts and drink breaks, so in those times users leave using the platform and back again, that's a normal scenario on any platform whether on TV or OTT platform.
- NOTE
If you closely look at the graph it shows that the maximum time number of live streamers is around 10M+ so you can think how powerful and reliable the infrastructure of Hotstar is.
- Rain Interruption causes a sudden drop
If you see from the graph at point 3 to point 4 there is a sudden drop because at the time NZ was batting and suddenly it started raining there causing the match to stop causing the drop from 13.9M live watchers to ~3M watchers.
Fun fact during point 4 in the graph people were still watching although there is nothing its just the rain on their screens and some highlights of match but people were still watching.
- Match continues on day 2
From point 4 to point 5, there is a rise in live users because there were some overs left for the NZ to bat on. After that the dip from point 5 to point 6 is because NZ batting was over and again there was a rise from point 6 because India Batting starts from there.
As you can see a sudden rise from 2M to ~13M and then suddenly drop to ~4M after a while is very dangerous for the platform, Your platform should be capable of handling all this sudden nature, also you cannot rely on Auto-Scaling as it is slow in nature.
- Teaser before the real trailer
During point 7th part of the graph IND bats and there was a regular fall of wickets and live users were around 16M at that time, also IND was losing at that particular point of time but suddenly Dhoni came to bat which raise the platform to live users from 16M to 25M+ live users.
Also at that time dhoni was playing very well and giving hope that now India will win the match and that's where Hotstar marketing team started sending Push Notifications to its users to bring more peoples into the platform to watch the match.
Also from point 7 to point 8 the rise which you can see live users were added to the platform at the rate of 1.1M users/min. and that sudden spike took in almost 10 min.
- The Real Game
At point 8 unfortunately Dhoni got out which leads the platform to a very dangerous drop from 25M+ live users to ~1M users.😱
Before dhoni gets out the number of live users was around 25M+ and that's the time Hotstar made the world record of handling this much amount of live users.
The sudden drops from 25M to 1M is what kills most of the platforms.
Let's understand how?
When you're watching a video then you're just requesting the video playback files, but at that time you're just watching the cricket match so there were just video API calls but not that much. Suddenly when you shift from video to home page now you're requesting the homepage request containing your personalized recommendation, past watched content tray, and some of your resume watching stuff. Imagine how dangerous it would be when all 25M users hit the back button to return to their home page because in the backend there will be API calls to every single service you're requesting, so your platform should be capable of handling those things because we don't know when the traffic will drop or rise so your platform should be prepared for it.
Scaling and the record


FACE THE REAL GAME BEFORE THE ACTUAL GAME

In order to make any platform reliable and scalable, there is a lot of large-scale testing to check how much load can an application handles.
In this case, hotstar team has an in-house project called "Project HULK" for testing their application. You can see from the above image how much infrastructure is used to generate the load for testing. Like creating load generation, performing Tsunami tests( The sudden hike and drop is an example of this ), Traffic patterns, and chaos engineering.
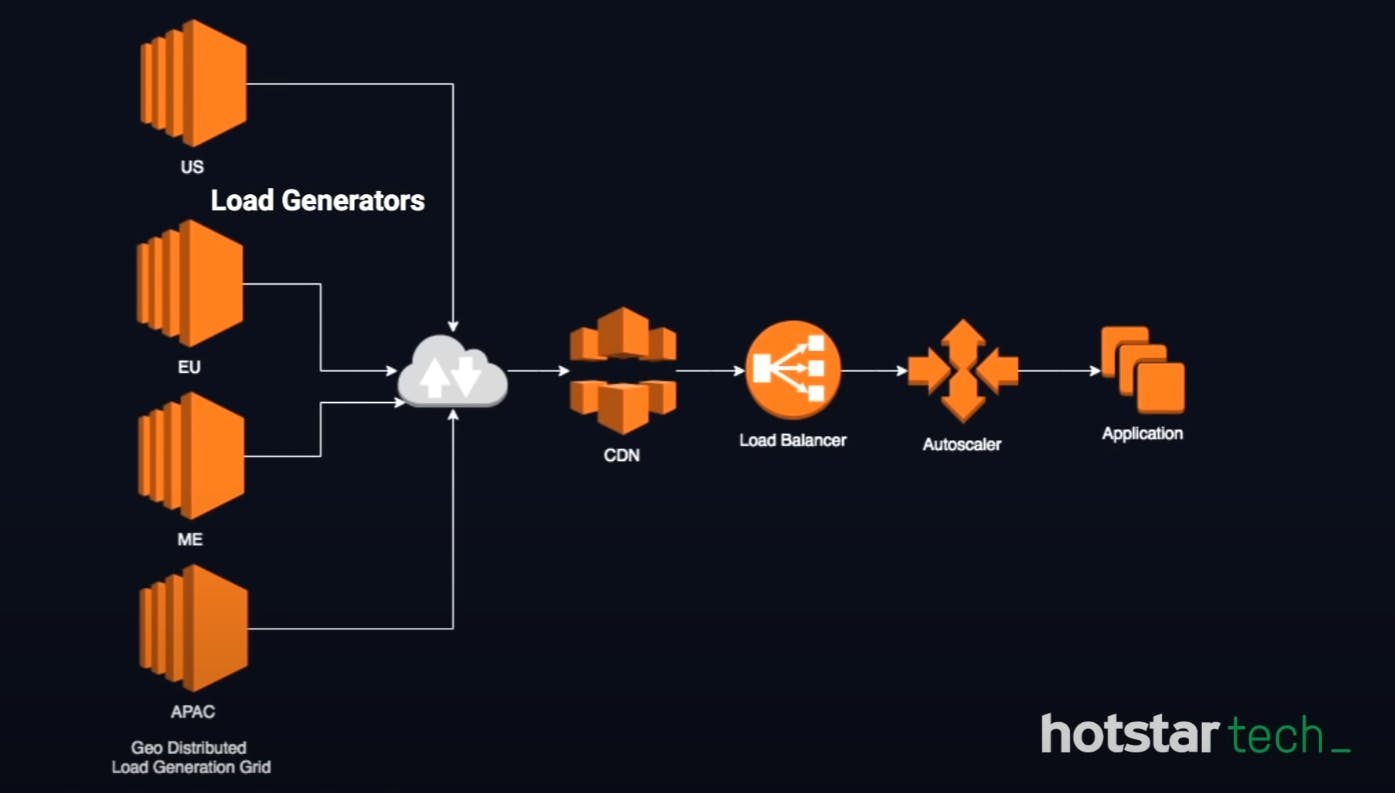
The above image shows us what the load generation infra looks like for generating the loads. Here c59 xlarge machine is distributed in 8 regions, goes to the internet, and then to CDN to load balancer to autoscaler and then to application. The load balancer has a peak value up to which they can handle the load but in this case, every single application of hotstar uses around 3-4 load balancers to handle the loads this is how the load is distributed and that is how they scale their application. The application can be hosted on ec2 or Kubernetes. This infrastructure is used for creating the loads to test their application.
Scaling Statistics

Here you can see that the growth rate is 1M per minute so the team has to scale up in advance because the traffic rate was so high and increasing rapidly. Reason behind advance scaling is because by the time ec2 will provisioned, then boots up and then the application become healthy under a load balancer so under this whole process 5-6 mins will get waste and in a live match you can support that because in 5-6 min the traffic will increase by 6-7M
Here you can see that the application boot time is around ~min and Push notifications were also there. Now Push Notification role here is to get more user when there is something interesting happen to gain the user attention.
FULLY BAKED AMIs are used here, the reason why the hotstar team use this instead of any other configuration tool like chef, puppet is because these tools configure after the server is up which ultimately add delay for the application to become healthy.
Why don't they use autoscaling?

For example, when you want to go from 10M to 15M you have to request a lot of servers from any cloud provider(AWS in this case). Let say you have 400 servers and now you wanted 200 more servers but what if you get only 50 extra servers and you didn't get the remaining 150 this can leads to insufficient CAPACITY errors.
Also there is a Single INSTANCE TYPE per auto-scaling group means if there is a different instance type that has more capacity they can scale the application using that but since ASG ( Auto Scaling Group ) only supports one instance type it creates a blockage.
STEP SIZE autoscaling groups When you request or increase your desired capacity in ASG, it adds server in a step size of 10 or 20. Let's say you scale up your application from 100 to 800 what it will try to add 10 or 20 servers in all availability zone and this process is very slow because if you want to go from 100 to 800 and you're adding every 10 secs or 30 secs and to provision 800 servers its gonna take around 10 - 15 min which cannot be acceptable when you're running a live game.
Also there are a lot of API throttling. When activities like this happen you can ask cloud providers to increase your service limit and allow to scale or increase the step size to maybe 100 or 200. but now you're doing more damage to the system because if 200 servers launch at one go, you are making 200 control plane API calls and these are multiple calls like run ec2 instance API call and then attach those ec2 instances to load balancer and some monitoring calls is also there because now your system is healthy and it will start reporting CPU and network metrics then there can be disk attachment API calls and this all happen in the background but it all uses your control plane and data plane API which is transparent to the user but at the scale, all those are fixed which cannot grow.
- Availability zones Issues
Let's say you have three availability zones A, B, and C. If C has less capacity and you try to increase the target capacity of your ASG(AWS), there is an internal algorithm it has it will try launching a server in all the three AZ ( Availability Zones ) so it will launch A(10), B(10) and C(10) means 10-10-10 servers in each availability zones. and now lets say C AZ has only 10 servers capacity left which we got now but in the second attempt it will again increase by 10 in each AZ but now C AZ doesn't have capacity to handle more 10 servers.
Also what happens is provisioning a server in a particular AZ is not in the control of the hotstar team because that is taken care by the internal algorithm that AZ has. So when you got error your application adds an exponential back off. So first it will try every 20 secs, if it fails, the duration increases to 30 seconds, then one, then 5 and goes on. So how this harms the scaling is that the infrastructure becomes skewed as they have more capacity in 2 AZ while in 1 AZ they're lacking and if something happens to one of the AZ like something went wrong or some fault happens now all the traffic is being served through the other AZ which may increase the scale time and delay the process.
Hotstar uses its own Auto Scaling
They didn't use the automatic scaling that AWS provides. Instead, they have developed their own auto-scaling tool. What it does is instead of scaling on default metrics like CPU, Network it instead scales up on request rate and concurrency.
They use a ladder kind of system, for example, like at 3 million each application has this many servers and so on.
Whichever metric is high, if the concurrency is high, it will scale that way. If the request count per application is high, it will scale using the request count as a metric. Instead of using CPU metrics they have settled up the benchmark like how much each server or each container can, like the rated RPM that each container can serve and basis on that they take decision.
CHAOS Engineering
For those who don't know what CHAOS Eng is, it's something like you find out breaking point in a system or kind of like art of breaking things so that you know that, okay, failure is about to happen, and how can you overcome it without impacting the user.

Push Notifications we already talked about above.
Increased Latency
Even if one application in your entire user journey is impacted, what happens is it has a cascading effect on other services as well. So let's say my content platform API's have increased their latency by 50 ms so what happens is there can be other services too that are consuming this API as well right to show content. So on your home page, let's say you have a personalized engine, a recommendation system engine, which shows what content you have watched and what you should watch.
So these API depend on the content platform API and if that API has increased latency this, in turn, will work slowly which load the homepage slowly or may increase the app startup time, So a single increase in latency anywhere in the systems can have a cascading effect to the entire application.
Network Failures
Scaling at this big level can lead to network failures and here we depend a lot on CDN providers. So what happens is, that if the edge location goes down or is overwhelmed, they have to reboot or ship traffic. Now all the traffic that was being served for a particular edge location closest to your home or ISP, all those requests will now come to the origin.
Think it like you're operating at 10 million and the edge location or anything like closer to your home went down. Now your request will directly come to the mid layer or the origin endpoint. If it comes to the origin and if the application is not scaled up to handle the origin requests it can actually bring down the application.
Delayed scale-up is the other reason why the Hotstar team doesn't use the auto-scaling, because if the infrastructure is not provisioned to handle the load in advance there are a high chance that the user might get affected and gets a bad experience.
Tsunami Traffic is the one we saw in the first graph the sudden hike and drop are equally bad for the application.
Bandwidth Constraints is another problem, with more and more user coming in, the application consumes a lot of video bandwidth, and the stats that we saw above clearly states that more than 10TB per second is used at that time which is almost running at 70% of India's capacity. So there is limited room to operate in terms of adding more users.
What the team finds out at the end?
- Undiscovered issues and hidden patterns
The main goal of CHAOS engineering is not to bring down the system, but in fact, find out what happens if one of your AZ goes down or you ran out of capacity or you have some network issues, will the application still perform?
- Check points
This thing is related to the things that cannot be scaled up in time especially data store and backend system which needs to be provisioned to a peak capacity because they are not that elastic in nature.
- breaking point of each system
As we talked about rated capacity earlier, the Hotstar team has developed a tool in-house that understands how much load each application can take.
So like what is the benchmark number or rated capacity for each microservice or application, which helps them to know at what RPS or TPS application can go down and then they take action accordingly.
- Death Wave
This tells the team to know how to handle the sudden spikes and drops and how to handle it. Although the Hotstar team was ready to handle up to 50M concurrency but that point won't come.
- Failures-network, servers, applications
They get to know how to handle network, server, and application failures.
- PANIC MODE

Even though when you're handling such pressure and high concurrent rate and a lot of users using the application what you can do is turning off the less necessary things to make a way for the critical services, here less necessary things like recommendation system, previously watched, suggestions and all because at that time user don't do a such activity with it.
KEY TAKEAWAYS
- Prepare for failures.
- Understand your user journey
- Okay to degrade gracefully
Conclusion
This is how Hotstar handles its users so well at the peak time of their application usability to maintain the highest record of handling this many live users at one time with almost zero downtime.
There is a lot of hard work of Engineers to provide their users with a very well experience and this is what "ENGINEERING" is.
Thanks for reading and I will see you in my next blog, Also you can follow me here Twitter