


My Internship Progress Report: Accomplishments and Modified Goals
Hello everyone!
As I reach the halfway point of my internship, I am excited to share the progress I have made on my project, implementing Artifact Mirroring for KCIDB. The goal of this project is to enhance the Linux Kernel testing systems by creating a triaging system for submitted results. This will involve downloading and storing artifacts, build and test logs, and tested patches in a reliable object storage system, allowing for long-term archiving and minimizing the risk of losing valuable information.
Below was the Original Internship Project Timeline:
Let's start with a quick recap of my original internship project timeline:
Week 1-2: Requirement gathering and Architecture design
Week 3-4: Setting up the infrastructure (object storage system and database)
Week 5-6: Developing the Artifact Download Service
Week 7-8: Integrating the Artifact Download Service with the KCIDB system
Week 9-10: Testing and Deployment
Week 10-12: Buffer weeks (for contingencies)
Goals Met in the First Half of My Internship:
I'm thrilled to share that during the first half of my internship, I successfully achieved the following goals:
Requirement Gathering and Architecture Design: I meticulously gathered requirements and analyzed the existing system architecture. This process helped me identify areas that needed improvement and allowed me to design a robust architecture for the Artifact Mirroring system.
This process took almost a month for me because it includes several things such as a prototype of what we are trying to build(my mentors gave me small tasks so that I got a feel about what this whole project feature is all about), Workflow structure, existing projects having kinda similar features to reduce future tasks(although we couldn't find anything like that, thanks to google :)) ), So we have to start from the base.

Huge shoutout to my mentors who were hosting a GCP project for me, so that I can test out my changes.
Some of the tasks include:
Creation of a simple Python function that can catch the contents from a URL given to it and store it into a folder and then a fetch function which can tell us where that file is located.
The first challenge here was that what if two URLs have a file which has similar names then? Well that would just overwrite the existing file and we lost our older file from a different URL. So I have to come up with a solution where the catching function should uniquely store the file so that file names won't clash with each other.
The function script I wrote above was taking too much time to cache the contents from the URLs list provided to it and to make our task seamlessly fast we came up with a solution of a Multi-process concurrency concept through which we can process requests in batches executing at the same time. I haven't applied that concept practically so this step took almost 3-4 days to implement a solution for this because I have to learn about it and then experiment with it.
The next step for me was to create an HTTP server that responds to the requested cache in the prototype I was creating which helps me understand how the URL redirection workflow works and how they get handled. I do have some basic knowledge about it but have to learn more about advanced topics of it like how status codes work, what different status codes suggest, and how they handle the request.
I have to also learn about the URL structure, how encoding and decoding work etc.
The next step was for me to extract the content disposition of the file URL, file type, file size, etc. This step was a challenging task for me because I didn't know that part of HTTP protocols through which we can get the info about the target file it holds. But it was a lot of learning for me to know about this.

Then as a next step, I've to run this prototype where it can store the files in the cloud storage. At this place I got to learn about the Google cloud storage library and gcloud CLI (This step also covers the research about the best cloud storage system for our artifacts where we compare different available options like Min.io, Azure storage and AWS S3 but ends up with Google cloud storage because most of our code is deployed on google cloud.
Then I tried to implement the cloud function and add my logic of cache to it and added the cache client in the project.
Then I created a script which extracts the url file information and store them in csv file. This process involves extracting urls from our test results file we got from different origins. With that csv file we created graphs to see what kind of data we get the most. Below are the charts we created.

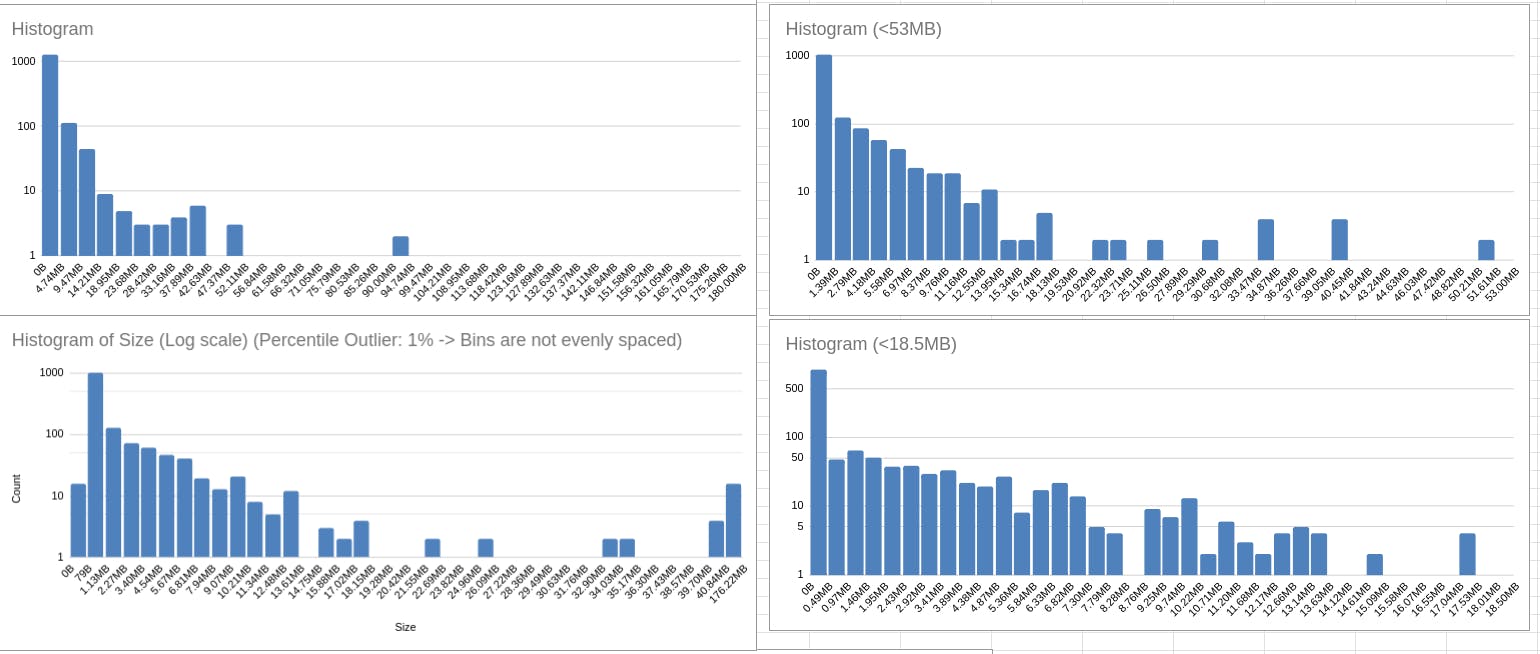
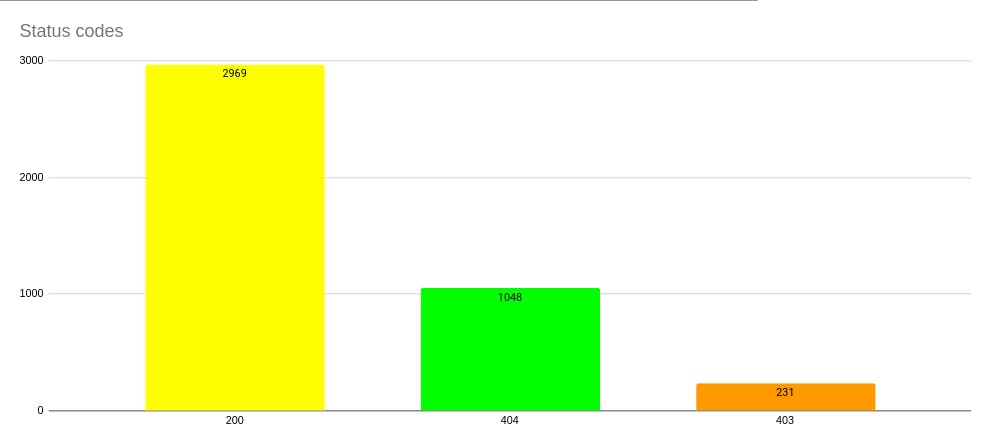
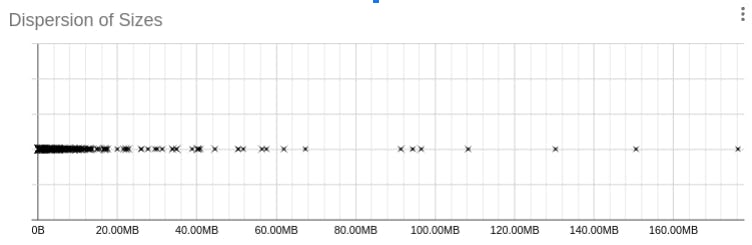
You can see above the sizes of the files we get against different filters.
(Thanks to my mentor Tales who helped us with the graph.)
Then I worked on Pub/Sub in google cloud and try to implement a separate topic for the cache URLs so that whenever a new message got published it triggers the cache client and cache the file from there and store it in the cloud storage. I didnt know about the Pub/Sub that much so I have to learn about it too and implement it in bash script to deploy that topic whenever we deploy our project.

Project Goals That Took Longer Than Expected and Reasons:
While my progress has been promising, some project goals took longer than anticipated. The primary reasons for these delays were:
Integration Complexity: Integrating the Artifact Download Service with the KCIDB system turned out to be more complex than initially envisaged.
Bash scripting Implementation: Took me some time to figure out how bash scripting works because I had no experience with it but I practised, learned and experiment with it to implement my tasks. It includes adding cloud functions in separate cloud function sections, addition of cache URLs topic etc
Unforeseen Challenges: Like any substantial project, we encountered unforeseen challenges along the way. Addressing these issues required careful problem-solving and adaptations to the implementation plan.
Lessons Learned and Modified Goals:
Looking back on the first half of my internship, I've gained invaluable insights that will influence the course of my project in the second half. If I were starting the project over, I would consider the following adjustments:
More Buffer Time: While I allocated buffer weeks in my original timeline, I've learned that additional buffer time is essential for handling unexpected complexities and ensuring a polished final product.
Improved Testing Strategy: In the second half, I will enhance my testing strategy by focusing on comprehensive unit tests, integration tests, and simulated load testing to identify potential bottlenecks and improve system performance.
Enhanced Documentation: Clear and extensive documentation is critical for maintaining and supporting the system in the long run. I will prioritize documenting every aspect of the Artifact Mirroring system for ease of maintenance and future development.
I am incredibly grateful for the support and guidance I received during my internship. I am confident that the Artifact Mirroring system will bring significant value to KCIDB and enhance the overall testing process. Special thanks to my mentors Nikolai and Tales for guiding me throughout every step.
Stay tuned for more updates on my progress and the final outcome of this exciting project!
Thank you for reading, I will see you in my next blog :))
