

Hi everyone, As my outreachy internship with KernelCI on their project KCIDB is about to end, I am here to tell you about the work I did, and what was the new feature I worked on. This is my final project progress blog post telling you everything about the new feature KCIDB now has support for.
What is KCIDB?
KCIDB is a package for submitting and querying Linux Kernel CI reports, coming from independent CI systems, and for maintaining the service behind that.
See the collected results on our dashboard. Write to kernelci@lists.linux.dev if you want to start submitting results from your CI system, or if you want to receive automatic notifications of arriving results.
The Problem Statement
The data KCIDB receives from Linux Kernel testing systems includes links to build configuration and artifacts, build and test logs, and sometimes tested patches. Currently, we're keeping these links as is, and rely on the submitting systems to maintain them in working order for as long as they can.
However, the next step of KCIDB development is implementing a triaging system for submitted results, which would look at the contents of the linked files, and determine if the results are exhibiting a particular known issue or several. For that purpose, as well as for long-term archiving, the KCIDB system needs to take ownership of those files and maintain their storage.
KCIDB Grafana Dashboard Glimpse
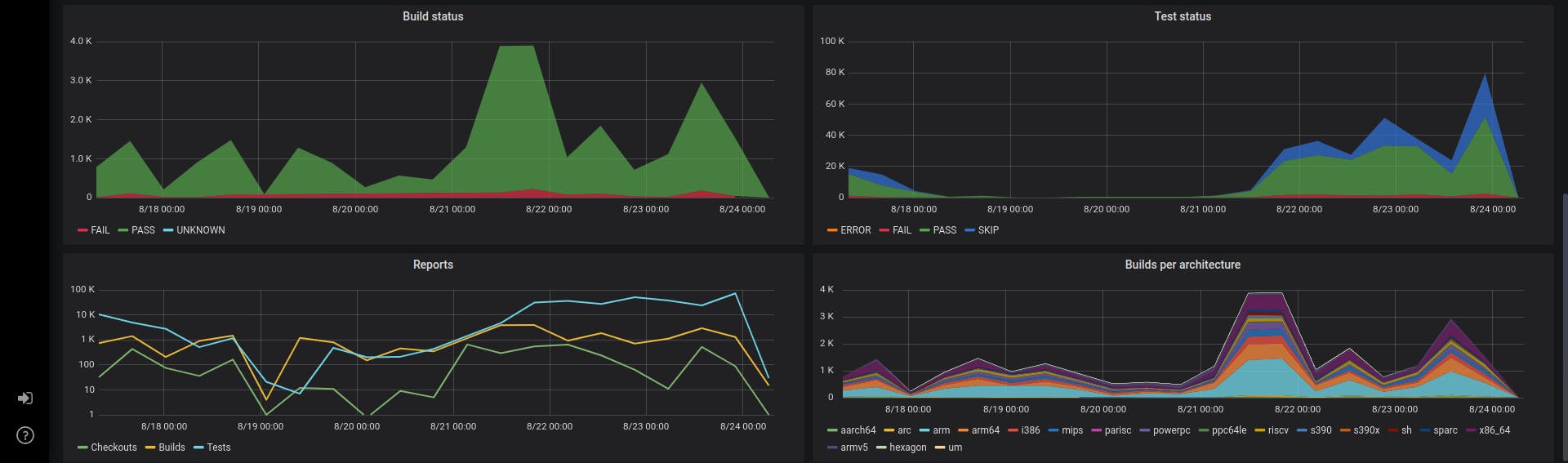
You can visit the dashboard here
My Work
Caching client
The KCIDB URL caching system is a Python module that provides a client class for caching and managing artifacts from upstream URLs using Google Cloud Storage. This module allows URLs' contents to be stored in KCIDB project GCS bucket if they meet certain size criteria which is currently 5MB. It offers functions to store, map the URLs with their file name, check, fetch, and empty cached content.
Separate Pub/Sub topic
Implemented a separate pub/sub topic for the artifact URLs whose contents need to be cached.
URL-caching cloud function
This function iterates through the extracted URLs and employs the caching client to store their contents in KCIDB Google Cloud Storage (GCS) bucket. This Cloud Function streamlines the process of caching content from Pub/sub-triggered events.
Storage support
I implemented GCS bucket storage support in KCIDB project to store the artifacts.
Cache redirect cloud function
This is an HTTP cloud function that can handle incoming HTTP GET requests for serving cache. When a GET request is received, the endpoint checks whether the requested URL exists within the cache. If found, it redirects to the cached content(which will be KCIDB storage URL). Conversely, if the requested URL is not found in our storage, the endpoint redirects to the original URL.
Cache system deployment support
Automated the deployment of the cache system to Google Cloud inside the existing deployment tool which is implemented in KCIDB cloud bash script.
System test functionality
Implemented the whole caching system workflow test support to check if the caching system is working the way it should. This test is implemented to work in an empty deployment environment.
KCIDB Grafana dashboard redirects update
I updated the project dashboard to include support for serving the file through the new cache system.
Caching system documentation and workflow
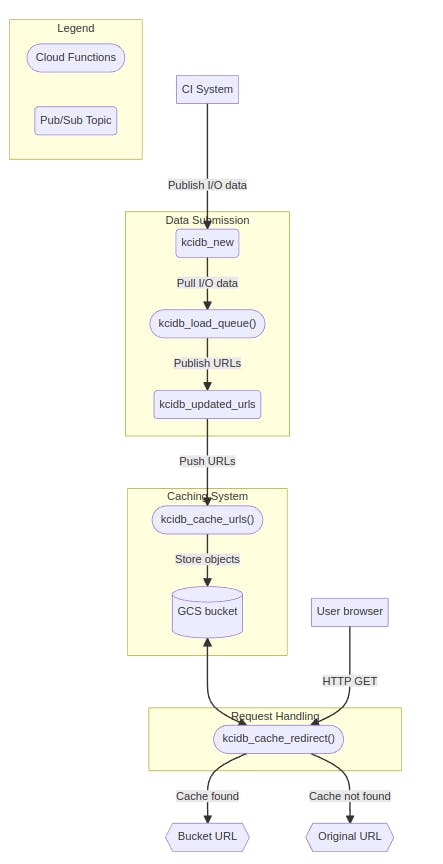
Wrote the documentation about the KCIDB caching system telling what the cache system does and how the whole workflow is working.
Below is the working described for the caching system:
Publishing Initial Data: The CI System initiates the process by publishing I/O data to the
kcidb_newtopic. This topic acts as a holding area for the data.URLs Extraction: The
kcidb_load_queue()function pulls the I/O data from thekcidb_newtopic, store it in the database and also extracts URLs from it. This extracted URL data is then published to thekcidb_updated_urlstopic.URL Processing and Cache Logic: The
kcidb_cache_urls()function receives the URLs from thekcidb_updated_urlstopic and fetch the file from that location and store them in the Google Cloud Storage Bucket.
Cache Request Handling
User File Request: When a user requests a file then that request is directed to the
kcidb_cache_redirect()cloud function. This function serves as the entry point for processing user requests and initiating the cache lookup process.Cache Lookup: The
kcidb_cache_redirect()function interacts with the Google Cloud Storage Bucket to find and serve the file from there, if it's available.File Availability Check: If the requested file is found within the cache storage, the
kcidb_cache_redirect()function performs a redirection to the location of the file within the Google Cloud Storage Bucket and serves it to the user.Fallback Mechanism: In cases where the requested file is not present within the cache storage, then
kcidb_cache_redirect()function redirects the user to the original URL from which the file was initially requested.
I am sure this new feature will help the developers more and reduce the number of cases of artifact removal from their organization URLs.
Huge shoutout to my mentors Nikolai Kondrashov & Tales L. da Aparecida, and the whole KernelCI community without them I couldn't achieved this new feature. Their guidance told me how to write clean code, how to understand the problem, and how to think while developing new features.
I will share my learnings in a separate blog post soon, with all this I will still be contributing to this project in the future too.
As I conclude my internship, I look back with a sense of pride and accomplishment at the journey I've undertaken. This project has not only deepened my technical understanding but has also taught me the importance of thinking and how to work on big projects. As I step into the next chapter of my career, I carry with me the valuable lessons, experiences, and memories from this internship. I'm excited to continue applying the skills I've honed here and to embrace new challenges with the same enthusiasm that has fueled my growth during this transformative internship.